- Published on
Harry Potter Books & Fanfiction - An Analysis of Words
- Authors

- Name
- Haider Ali Punjabi
- @HAliPunjabi

Background
On 28th May, a post on r/dataisbeautiful inspired me to learn how to make Word Clouds myself. Being a huge Harry Potter fan, the data I was going to use was obvious. Using the Books seemed too simple so I decided to scrape 250 stories from Fanfiction.net , and make a Word Cloud from that data. I posted my first attempt on r/dataisbeautiful, and based on the feedback I received, I decided to write this blog.
The entire source code (except the data files & output files) is available here
Attempt 1
There are many approaches I could have taken to prepare the data. I decided to download the stories first and then do the processing on the local files due to my slow & unreliable internet.

Scraping Fanfiction
I used simple Python + BeautifulSoup combination to scrape the stories form Fanfiction.net. I sorted the stories based on their Favorite Count, and filtered them to stories having more than 100k words. (Link to the URL). I scraped first 10 pages, (each page has 25 stories) resulting in 250 stories. It took me a total of 10 hours (7 on one day, and 3 on the next) to scrape all the stories.
from bs4 import BeautifulSoup as soup
import requests
import json
main_url ="https://www.fanfiction.net/book/Harry-Potter/?&srt=4&r=10&len=100&p=%s"
base_url = "https://www.fanfiction.net"
freq = {}
count = 0
def story_generator():
for i in range(1,11):
r = requests.get(main_url%(i))
s = soup(r.text,features="html5lib")
stories = s.findAll('a',"stitle")
for story in stories:
global count
count += 1
print("Yield %s: %s"%(count,story.text))
yield story.attrs['href']
def generate_frequency(words):
for word in words:
if word in freq:
freq[word] += 1
else:
freq[word] = 1
def scrape_chapter(url):
r = requests.get(url)
s = soup(r.text, features="html5lib")
return s.select_one(".storytext").text
for storyurl in story_generator():
r = requests.get(base_url+storyurl)
s = soup(r.text,features="html5lib")
chap_select = s.select_one("#chap_select")
chapters = int(len(list(chap_select.children)))
file = open("fics/%s.txt"%(storyurl.split("/")[2]),"w")
for i in range(1,chapters+1):
url_parts = storyurl.split("/")
url_parts[3] = str(i)
file.write(scrape_chapter(base_url+"/".join(url_parts)))
file.close()
Processing the Data
Taking hints from the original post, I used nltk to tokenize the stories, and removed the common words from the nltk English Stopwords Corpus. This was my first attempt at doing anything like this, and the process was taking 3-4 minutes per story initially. After some optimization, I was able to reduce the time to 1-2 minutes per story. I talked to a friend about the problem, and he suggested me to try multiprocessing. After adding multiprocessing, I had the idea of distributing the load over two CPUs (my laptop and a Raspberry Pi 4B). I copied the script and 25% of the stories over to the Pi and started the job.
Additional Tip: screen is a good utility to do long jobs over SSH
It took me an hour to the processing. I didn't want to do the processing again if I needed to remove some more words so I decided to store the word frequency data into json files. (Really helpful in future)
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import os
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import json
import multiprocessing as mp
source_directory = "books"
data_directory = "bookdata"
source_files = [f.split(".")[0] for f in os.listdir(source_directory)]
done_files = [f.split(".")[0] for f in os.listdir(data_directory)]
files = []
gfile = open("custom_stopwords.txt","r")
to_remove = [l.strip() for l in gfile.readlines()]
stopwords = stopwords.words('english')
stopwords.extend(to_remove)
# Creating a list of already done files in case the process gets interrupted
for file in source_files:
if file not in done_files:
files.append(file)
file_count = len(files)
def process(i):
data = {}
file = open(f"{source_directory}/{files[i]}.txt","r")
print(f"Starting {i}: {files[i]}")
text = file.read()
tokens = word_tokenize(text)
## Not doing text.lower() to maintain the case of the words
for word in tokens:
if word not in stopwords and word.isalpha() and word.title() not in stopwords and word.lower() not in stopwords:
if word in data.keys():
data[word] += 1
else:
data[word] = 1
print(f"Done {i}/{file_count}")
data = {k: v for k, v in sorted(data.items(), key=lambda item: item[1],reverse=True)}
json.dump(data,open(f"{data_directory}/{files[i]}.json","w"))
pool = mp.Pool(mp.cpu_count())
results = [pool.map(process,range(file_count))]
pool.close()
Making the Word Cloud
I took a look at wordcloud Python Package and copied the code from its examples to generate the word cloud.
To make the mask image, I downloaded some images from the Internet and used Inkscape to fix them.
import os
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import json
# mask = np.array(Image.open("masks/book7.png"))
data = json.load(open("extra/genre.json","r"))
# print(f"Diffrent Words: {len(data.keys())} | Total Words: {sum(data.values())}")
wc = WordCloud(width=512,height=512,background_color="white", max_words=2000,
max_font_size=40, random_state=42,contour_width=1)
wc.generate_from_frequencies(data)
s = wc.to_svg()
print(s,file=open("out/genre.svg","w"))
Feedback
After posting the first attempt over at Reddit & Twitter, I received a lot of feedback. Common among them were the queries about why is Daphne more frequent and why is Ron less frequent (I will answer both later), suggestions to remove more words to focus it more on Harry Potter related words, and to show some other visualisations, especially ones comparing the books and fanfiction.
Attempt 2
Finding more stopwords
In my first attempt, I used the nltk English stopwords corpus, which is just 179 words. I searched for a bigger list and ended up using a customised 20,000 most common words list from google-10000-english repository. What were the customisations? I had to remove some words (like magic, magical, wand, wards, vampire, etc) and some names (Harry, Ron, Fred, Arthur, etc) from the 20k list so that they aren't removed from my analysis. Storing the results of the processing from my first attempt into json files saved me from spending another hour of processing. I just removed the necessary keys from each data file.
Harry Potter Canon Books
I also downloaded the text versions of the 7 books from somewhere on the Internet, sanitised them a bit, and applied the same process as the fanfiction stories to generate their data. Using that data, I was able to compare the occurrence of some words in fanfiction vs canon. Since I had the data and the code, I decided to make their corresponding word clouds as well.
Visualisations from Attempt 2:
Frequently Occurring Words in Top 250 Fanfictions

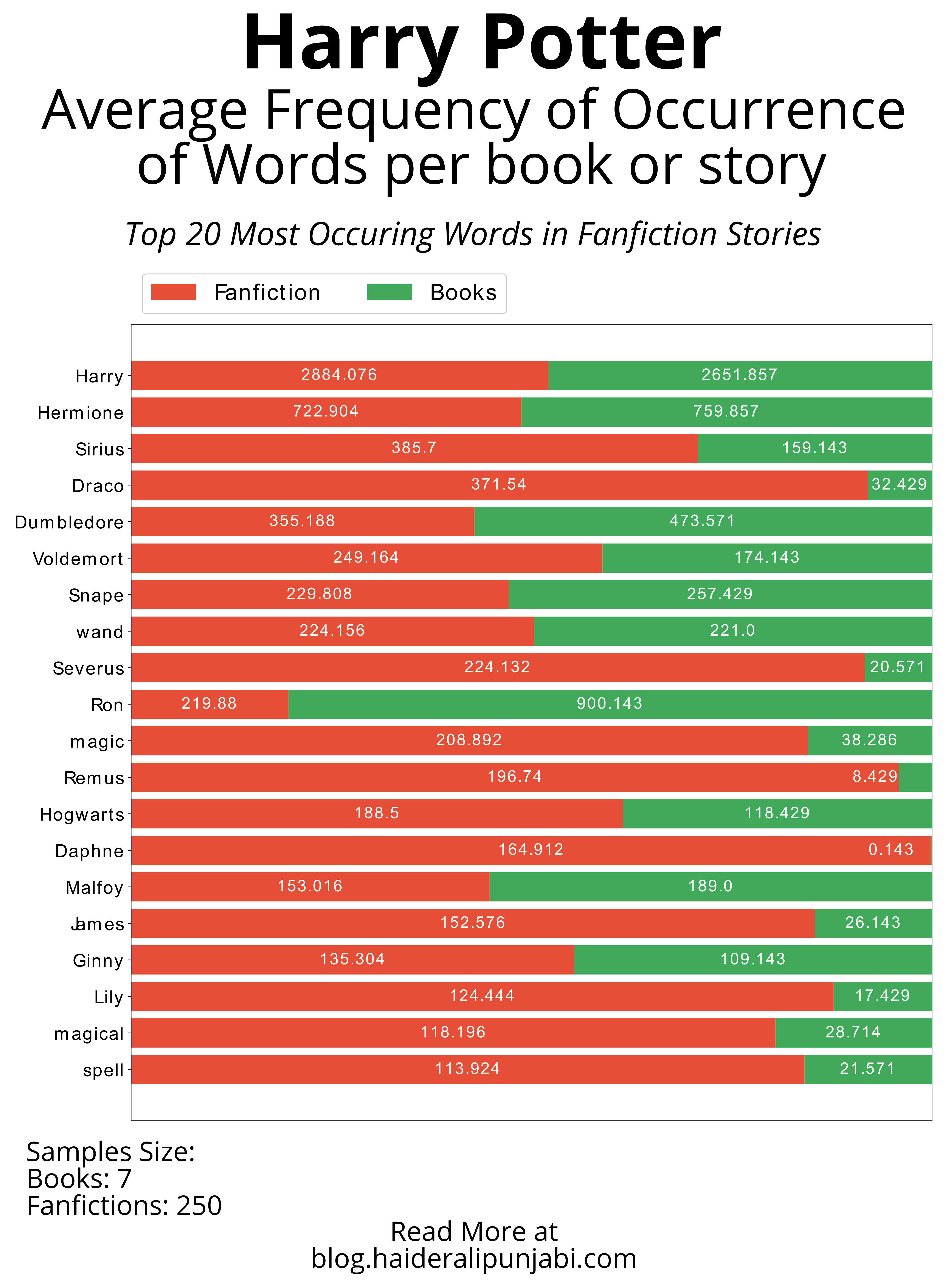
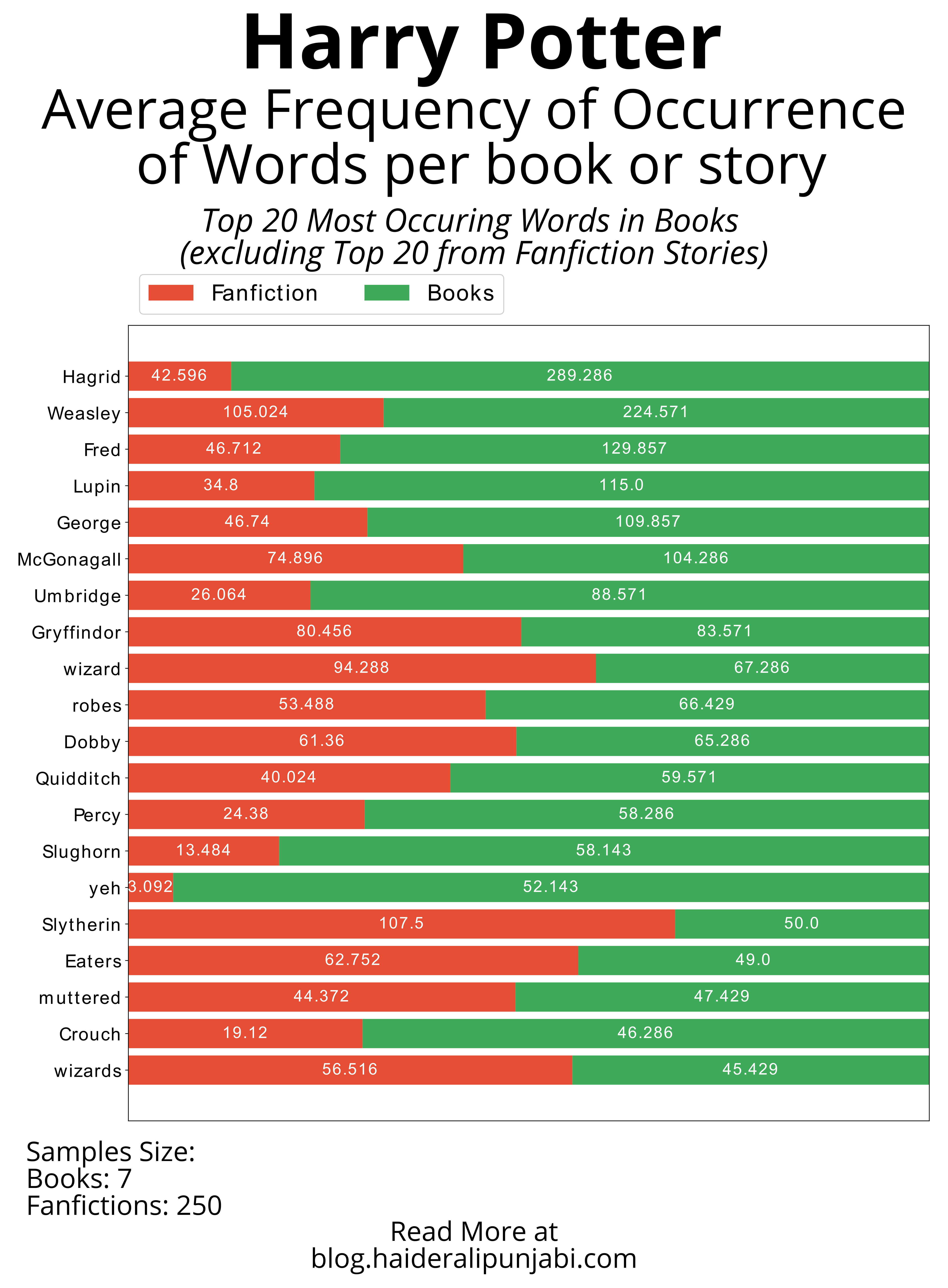
Average Frequency of Occurrence of Words per book or story
- Top 20 Most Occurring Words in Fanfiction Stories
- Top 20 Most Occurring Words in Harry Potter Books (excluding Top 20 from Fanfiction Stories)
Code to generate the above visualisations
import json
import os
import numpy as np
import matplotlib.pyplot as plt
import copy
ficdata = json.load(open("ficdata.json","r"))
bookdata = json.load(open("bookdata.json","r"))
ficscount=250
bookscount=7
category_names = ['Fanfiction', 'Books']
def generate_data():
data = {}
for key in list(ficdata.keys())[:20]:
word_data = [ficdata[key]/ficscount,0]
if key in bookdata.keys():
word_data[1] = (bookdata[key]/bookscount)
data[key] = word_data
## Graph 2
# for key in list(bookdata.keys()):
# if len(data.keys()) >= 40:
# break
# if key not in data.keys():
# word_data = [0,bookdata[key]/bookscount]
# if key in ficdata.keys():
# word_data[0] = (ficdata[key]/ficscount)
# data[key] = word_data
return data
def normalize_data(data):
for key in data.keys():
total = data[key][0] + data[key][1]
data[key][0] = data[key][0]*100/total
data[key][1] = data[key][1]*100/total
return data
def survey(results, category_names, ann):
"""
Parameters
----------
results : dict
A mapping from question labels to a list of answers per category.
It is assumed all lists contain the same number of entries and that
it matches the length of *category_names*.
category_names : list of str
The category labels.
"""
labels = list(results.keys())
data = np.array(list(results.values()))
data_cum = data.cumsum(axis=1)
category_colors = plt.get_cmap('RdYlGn')(
np.linspace(0.15, 0.85, data.shape[1]))
fig, ax = plt.subplots(figsize=(16,16))
ax.invert_yaxis()
ax.xaxis.set_visible(False)
ax.set_xlim(0, np.sum(data, axis=1).max())
for i, (colname, color) in enumerate(zip(category_names, category_colors)):
widths = data[:, i]
starts = data_cum[:, i] - widths
ax.barh(labels, widths, left=starts, height=0.8,
label=colname, color=color)
xcenters = starts + widths / 2
r, g, b, _ = color
text_color = 'white' if r * g * b < 0.5 else 'darkgrey'
for y, (x, c) in enumerate(zip(xcenters, widths)):
if(c < 5):
x -= 5
ax.text(x, y, round(ann[y][i],3), ha='center', va='center',
color=text_color,fontsize=18)
ax.yaxis.set_tick_params(labelsize=20)
ax.legend(ncol=len(category_names), bbox_to_anchor=(0, 1),
loc='lower left', fontsize=25)
fig.savefig("out/graph2.eps",format="eps")
fig.savefig("out/graph2.png",format="png")
data = generate_data()
## For Graph2
# for k in list(ficdata.keys())[:20]:
# print(k)
# del data[k]
norm_data = normalize_data(copy.deepcopy(data))
survey(norm_data,category_names,list(data.values()))
Important Results
Who is Daphne? Why is she so popular in Fanfiction?
Hermione’s name was called. Trembling, she left the chamber with Anthony Goldstein, Gregory Goyle, and Daphne Greengrass. Students who had already been tested did not return afterward, so Harry and Ron had no idea how Hermione had done.
-> Harry Potter and the Order of the Phoenix
Daphne Greengrass is an almost non-entity in canon, and a blank slate for fanfiction writers. In canon & most fanfictions, she is the sister of Astoria Greengrass (another almost non-entity) who becomes the wife of Draco Malfoy. In fanfictions, she is usually a Slytherin due to her ambitions & cunningness & not because of being a Pureblood Supermasict. Her family is depicted as Light or Grey, and support "Lord Potter". She is a popular pairing in Independent Harry stories.
Her being a blank slate character-wise is a boon for writers who want to write an OC without explicitly mentioning it.
Video explaining Daphne Greengrass and her popularity
What happened to Ron?
Ron is an almost opposite of Daphne. JKR wrote Ron in such a beautiful manner that many fanfiction writers are unable to write a good Ron. In canon, Ron is flawed but is also very funny, brave and loyal to his friends. In fanfictions, especially where Harry is very different to canon (Independent, Super-Powered, Lord Potter, etc), Harry usually ignores Ron (if diverging before Hogwarts) or the author does a lot of Ron bashing to justify Harry breaking up their friendship.
Bonus Visualisations
The 7 Canon Books:
- Philosopher's Stone
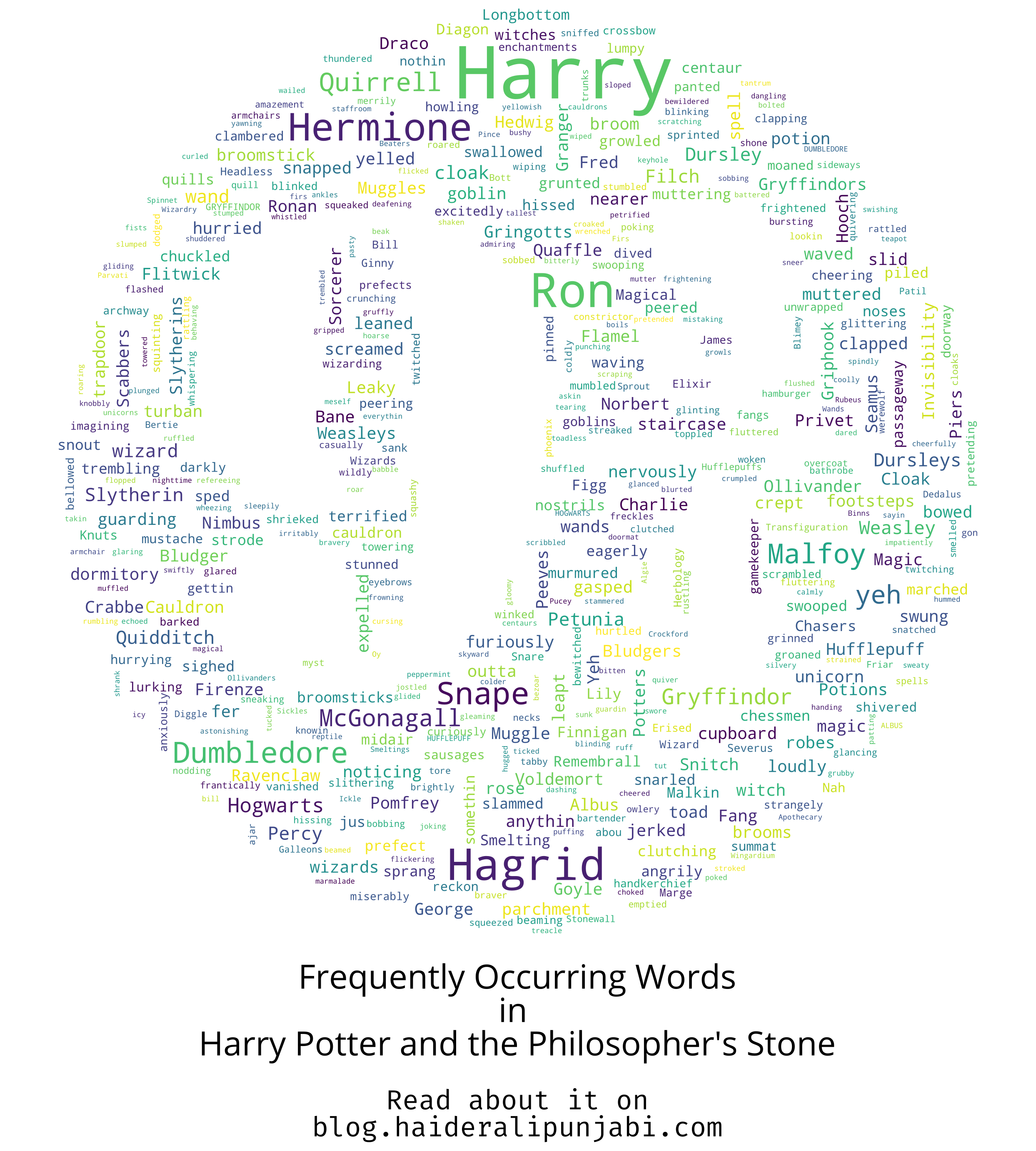
I tried to use an image of 9 3/4 . The word Quirrell and Griphook are frequent in this book and will lose their frequency in future books.
- Chamber of Secrets

I used an image of Dobby the Free Elf. You will words like Dobby, Lockhart (I hate that guy), Polyjuice, Parseltongue, Mandrakes, Mudbloods making an appearance in this book.
- Prisoner of Azkaban

I used an image of Prongs (James' Marauder Nickname, and Animagus form. Harry's Patronus) for this book. Words like Lupin, Sirius, Pettigrew, dementors, Crookshanks, Patronus start appearing.
- Goblet of Fire

I tried to use an Image of the Triwizard Trophy. Words like Cedric, Beauxbatons, Crouch, Durmstrang start appearing.
- Order of the Phoenix
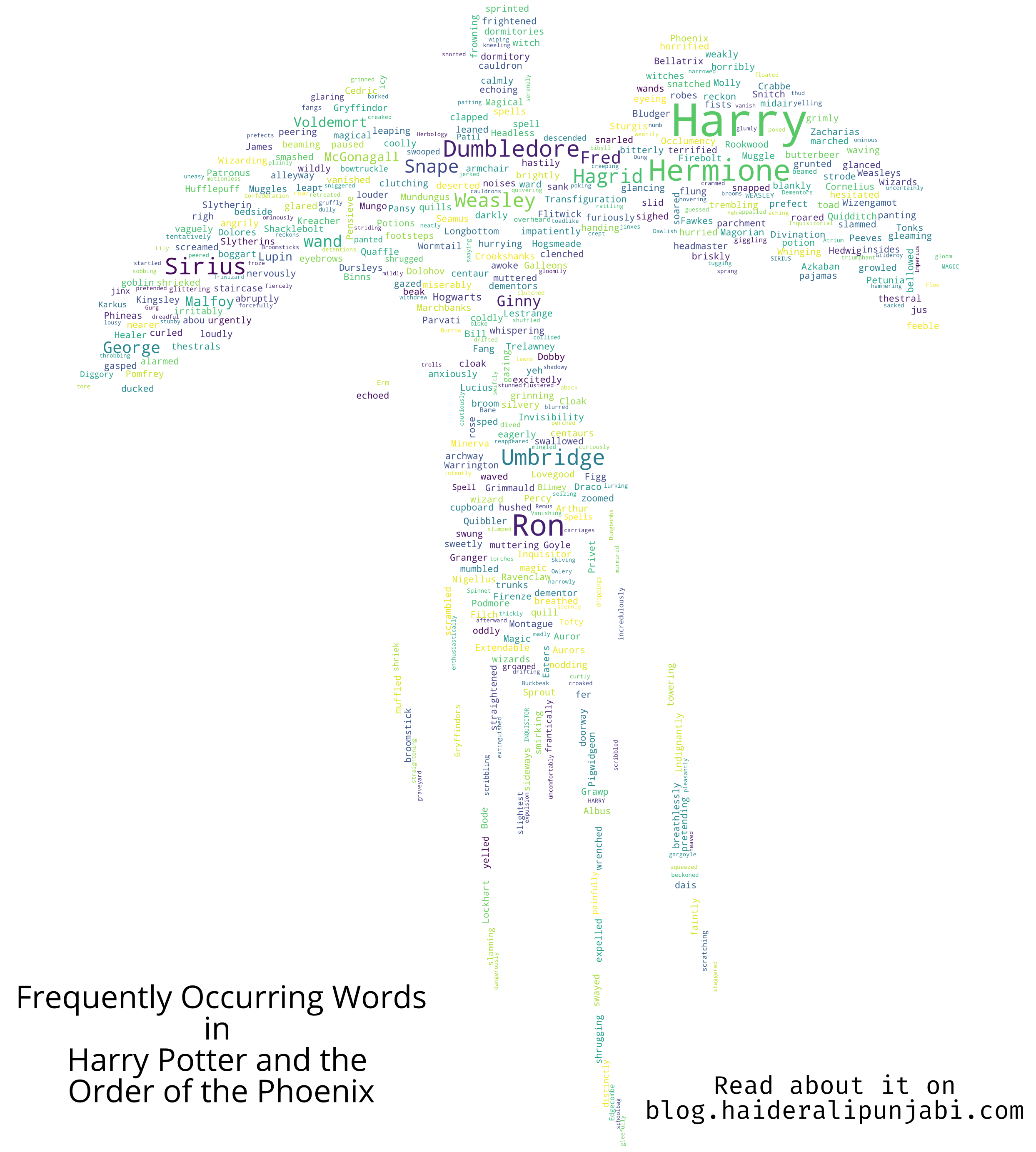
Tried to use an image of a Phoenix. Umbridge is very popular in this book.
- Half Blood Prince

I used an image of the Half Blood Prince for this book. Apart from the usual, Slughorn is the most common word in this book.
- Deathly Hallows
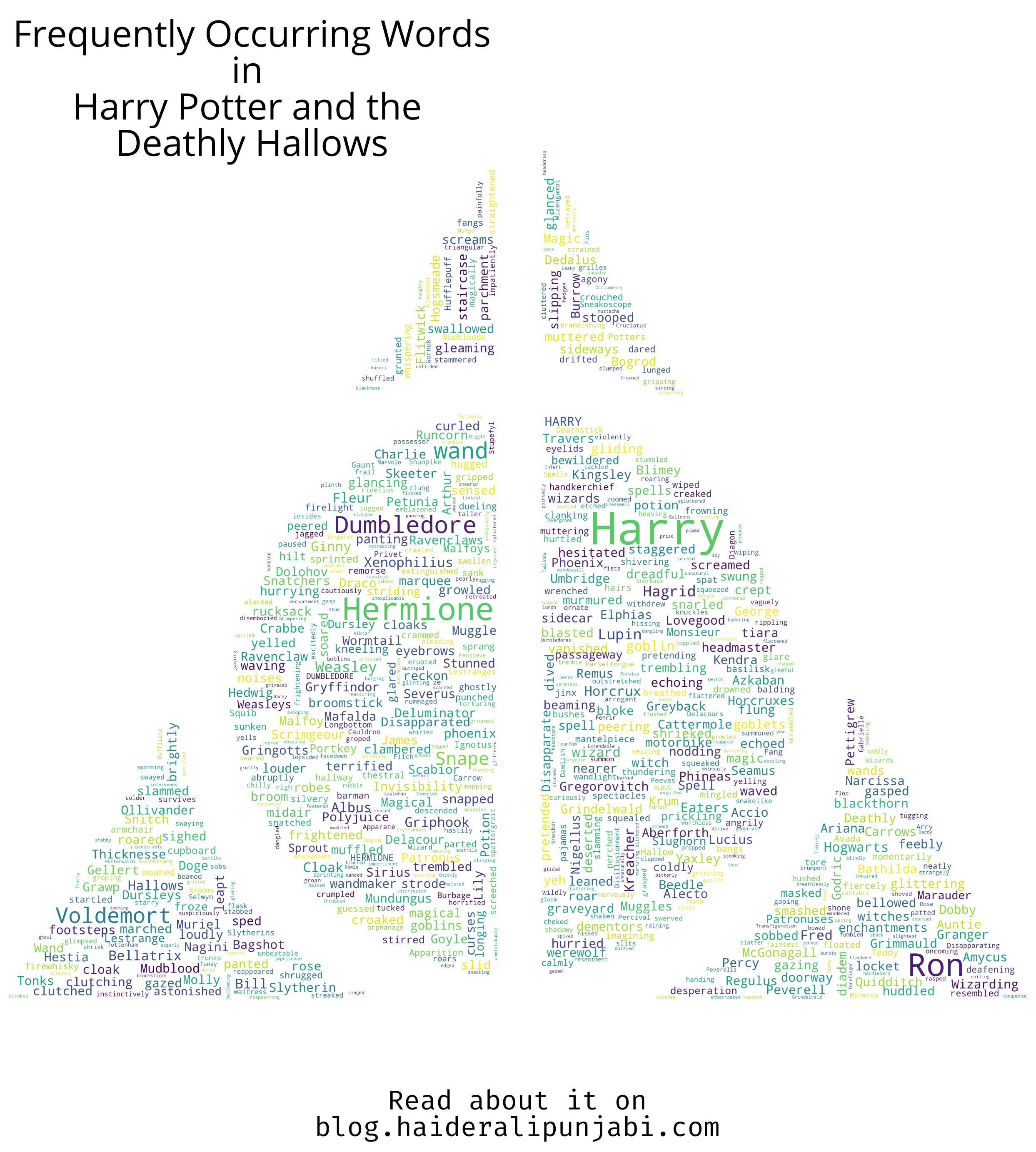
I used an image of the Deathly Hallows for this. You will see "wand" becomes very used due to "Elder wand". Hallows, Cloak, Wandmaker appear. Also, Griphook is back.
Future Plans
I am planning to scrape AO3 in the future to do some more analysis. I might also create some other Word Clouds from other popular books.